

DATA ANONYMIZATION – BACKGROUND
A resource for Guideline 1.4
SHARE THIS RESOURCE:
Created by: NYC Mayor’s Office of Technology and Innovation
Last Updated: July 27, 2017
Introduction
Data anonymization is the process of removing or modifying identifying information from data records. It is a type of information sanitation whose main goal is to protect the privacy of the people whom the dataset describes. There are multiple methods to achieve data anonymization, some of which are discussed in this paper. These methods include:
- Encryption – modifies data into code
- Perturbation – modifies values in a small way that does not affect analysis
- Substitution – substitutes values in different ways
- Aggregation – makes records look the same, or nearly the same
- Differential privacy – adds/modifies random values in a way that does not drastically affect analysis
Each of these techniques has advantages and disadvantages depending on the use case.
Encryption
Encryption modifies data into code, preventing outsiders from being able to easily read the original data. This keeps the integrity of the data (e.g. the data is whole and unchanged) while keeping it from being easily accessed. Encryption is useful when data cannot be modified before it is analyzed. The data will be difficult for attackers to read, but will remain the same for statistical analysis. However, because of this benefit of using encryption, data can also be stolen easily if the encryption is broken. Encryption can be used together with other methods listed in this paper, but should not be the sole step towards anonymizing data unless absolutely necessary.
CASE STUDY
A recent example where encryption proved insufficient to anonymize and protect data is the New York City cab driver logs. The logs contained information regarding each taxi trip made, including the “hack license numbers” (a driver’s permit to operate a taxi) and medallions of each taxi. While the hack license numbers and medallions were encrypted using a technology called MD5, this was not enough to prevent the information from being discovered. Each number had a predictable structure. Taxi license numbers are all six- or seven-digit numbers that begin with the number 5. Medallions are structured in one of three ways:
- One number, one letter, two numbers – ex. 5X55
- Two letters, three numbers – ex. XX555
- Three letters, three numbers – ex. XXX555
Because both these sensitive pieces of data have a finite number of possible values (two million possibilities for license numbers and twenty-two million possibilities for medallions), they are an easy target for cyberattacks. In addition, because of the version of MD5 used, no matter how many times a number was encrypted it will always result in the same encrypted value. An attacker could simply make a list of all possible license numbers and medallions, figure out the encrypted form of each number, and compare it to the taxi trip data. With modern computers and encryption cracking technologies, it took attackers a couple of hours to determine every number in the dataset.
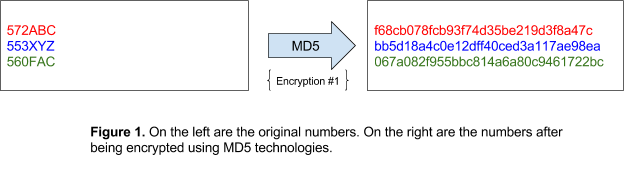
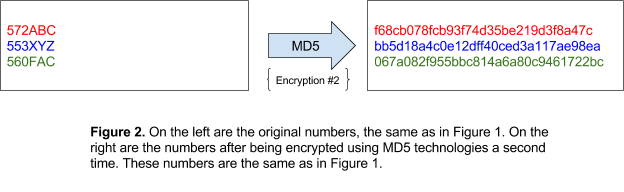
Perturbation
Perturbation is an approach to anonymize data by changing the values in a small way that will not affect the overall analysis. There are multiple methods of perturbation, the most useful for human data being microaggregation. Microaggregation sorts personally identifiable information in some order determined by the user. Then, the data is grouped into groups of similar numbers and averaged together. The mean of each group replaces the original value. This anonymizes the data by removing the exact values, but also does not drastically affect the analysis of the numbers.
The figure below illustrates this method of perturbation:
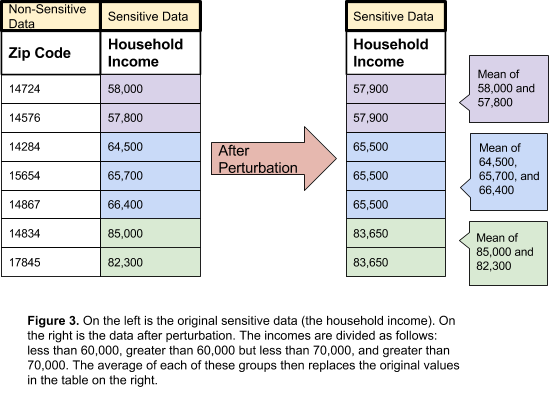
Other methods of perturbation include data swapping, post randomizations, and noise addition. In data swapping, pairs of data are swapped. The same data is present in the dataset, but now the locations and records are different. Post-randomization randomizes some values based on a mathematical sequence of probability. Like data swapping, the data remains in the dataset, albeit in different locations. Finally, adding noise adds random values to the data. By adding noise, the dataset now contains false data. The false data should not affect the statistical analysis of the overall dataset, but will assist in keeping data private.
Perturbation can be used in concert with other methods discussed later in the paper, specifically aggregation. Provided exact numbers are not required, perturbation will help anonymize data.
Substitution
Substitution anonymizes data by replacing the original value with a different value. This anonymizes the data while still retaining it in some form for statistical analysis. There are several ways of accomplishing substitution. The first is to simply substitute non-sensitive information with other, random values. In such a situation, even if an attacker does gain access to the data, it will be difficult to connect the sensitive information to the original non-sensitive information.
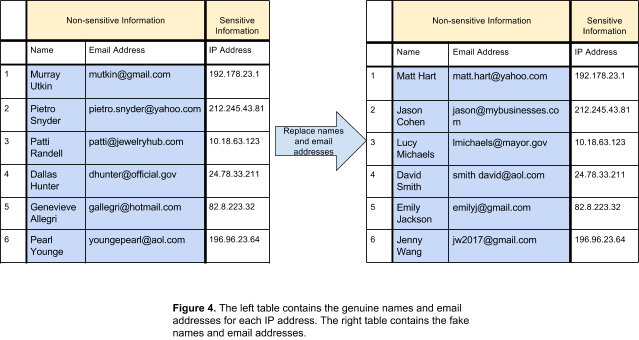
A second way to achieve substitution is by replacing values with placeholders. A key with original values and their respective placeholders is held by the owner of the data and is used to translate the anonymized values to the original ones.
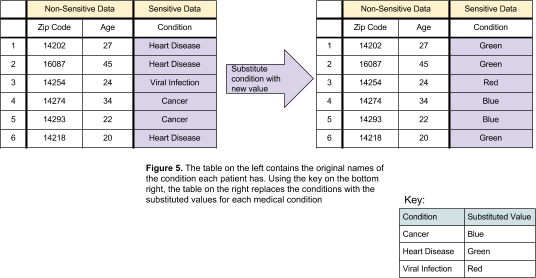
In the first method of substitution, if the non-sensitive data is not required and the randomization of data is done correctly, substitution is enough. For the second method, if the key is kept as secure as possible (e.g. offline, or on external media), substitution could be one of the methods involved in anonymization.However, there is always the possibility that an attacker can gain access to the key. This vulnerability must be taken into account when considering substitution as an anonymization technique.
Aggregation
Aggregation groups one data record with other records that have some or all data in common. When the records are released, it becomes impossible to determine personally identifiable information from non-sensitive data; there are multiple records that differ only in the sensitive data they hold. This is illustrated in the following figure:
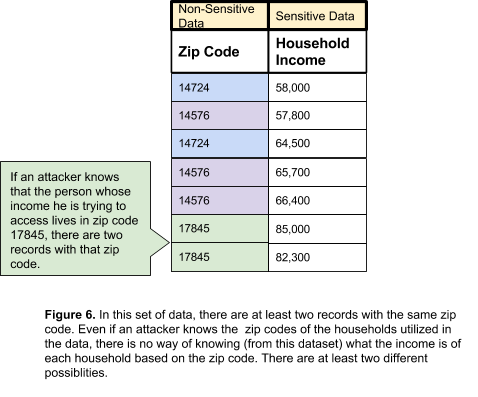
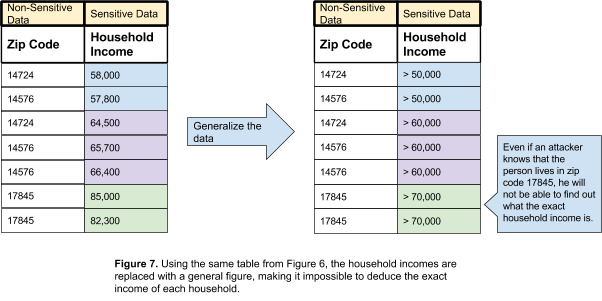
One way to achieve aggregation is through K-anonymity. K-anonymity tries to prevent re-identification by removing some data from multiple records, but still keep the data intact for future analysis. In this technique, when releasing records for use there are similar values between two or more records (as seen in Figure 6, above). For example, a group of household incomes may include a zip code. When this data is released, there should be at least two records with the same zip code. By doing this, it is impossible to determine which address each household income belongs to based on the zip code.
Generalization is one way to achieve k-anonymity. Generalization removes specificity from the data/records. Continuing with the previous example of household incomes, the income amounts will be replaced with a general value. Instead of recording the income as $57,000, the record may state that the income is “more than $50,000”.
Data suppression is another way of achieving k-anonymity and can be achieved in multiple ways. When data is suppressed, the values are removed from the records completely. Those values are replaced with an asterisk.

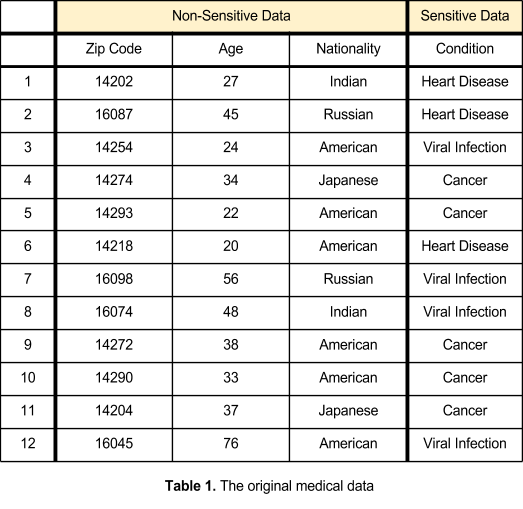
An extension of k-anonymity is L-diversity. K-anonymity can be subverted by an interference attack, an attack in which the attacker reverses the visible values to the real ones. An attacker may have background knowledge giving him the ability to deduce the original record, or multiple records may be the same, meaning an attacker need not know exactly which record is the one he is searching for. If an attacker has background knowledge, such as a zip code and age, it is possible to determine what sensitive information belongs to the person whose data is being stolen (see Table 2). If multiple records contain the same nonsensitive data, an attacker will not require exact knowledge to determine what the original record contained (see Table 2). In l-diversity, each field has at least l different values. Non-sensitive data is generalized (ages are categorized as greater or less than 40) and suppressed (nationalities are replaced with an asterisk) to create blocks of data that are the same, leaving the sensitive data as the sole identifier of the record. This makes it more difficult for an attacker to determine which record is the one he is looking for. The tables below illustrate the use of l-diversity:
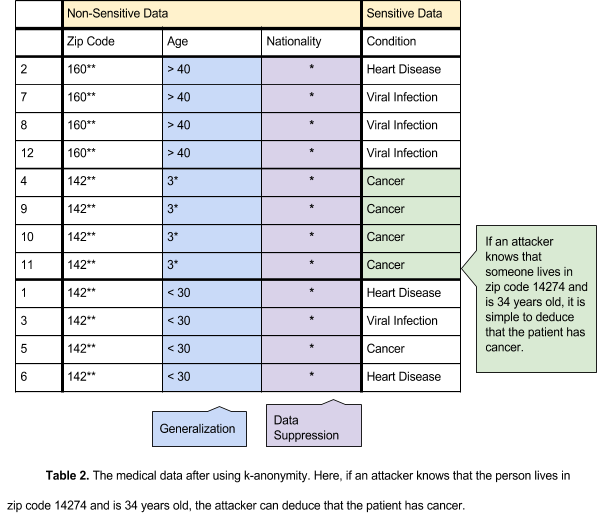
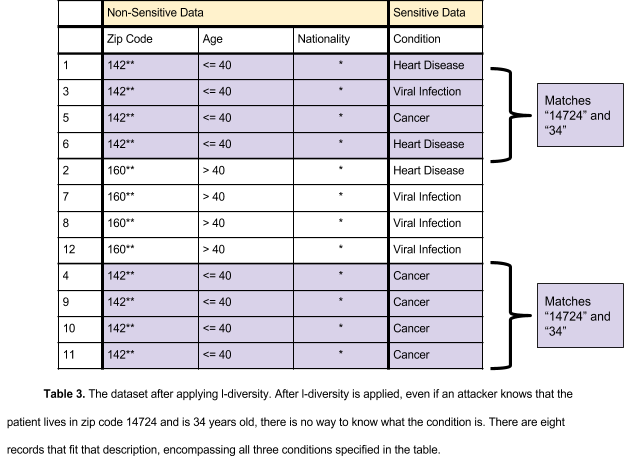
K-anonymity, when used correctly, is a one of the best techniques for data anonymization. It makes deducing sensitive data more difficult through the use of different techniques including generalization and data suppression. However, aggregation (and by extension, k-anonymity) has its flaws. If a dataset is re-released, there could be a change that will allow attackers to deduce personally identifiable information, as seen in the following example.
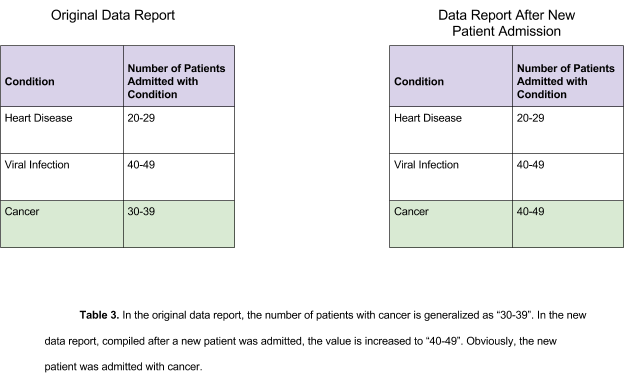
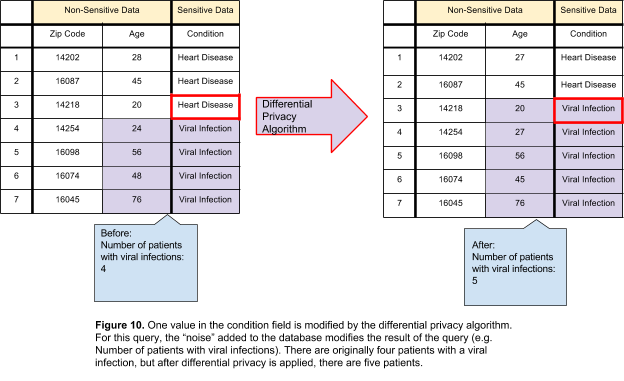
Differential Privacy
Differential privacy works to keep queries as accurate as possible while also reducing the possibility of an attacker successfully identifying records. It achieves these goals by adding a mathematically calculated amount of noise (e.g. small, random values that will not drastically affect analysis) to the dataset. Differential privacy can be simplified by asking a simple question: if there are two databases, one with sensitive information and one without, will a statistical query on both databases return similar results? If the answer is yes, the dataset is secure. If not, the records will have to be modified to prevent sensitive information from being leaked.
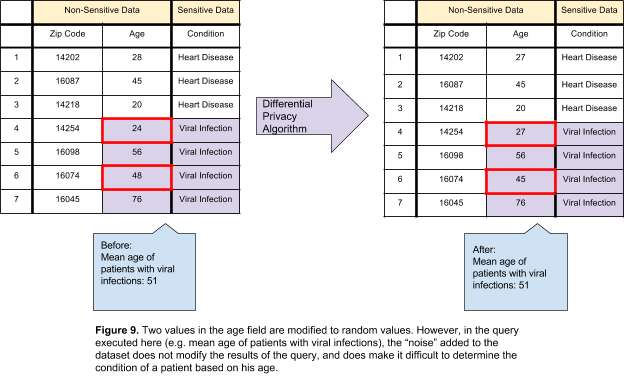
Differential privacy does not differentiate between information that is designated as sensitive and that which is designated as non-sensitive. In this method, all data is viewed as having the possibility to identify a person and treated accordingly. Noise is added to all fields in the dataset, regardless of whether it is sensitive or nonsensitive.
Differential privacy allows for a predetermined volume of information to leak during the lifetime of the dataset, based on mathematical calculations. An important consequence of differential privacy to keep in mind is that the amount of leakage will either rise or remain constant with each query on the dataset. This brings up two concerns:
- There is a direct correlation between the amount of noise added to the dataset and the amount of information you intend to query. If queries are intended to return a large amount of information, a large amount of noise must be added.
- Once data has been leaked and the amount added to the total information leakage, it has been leaked. There is no way to reduce the amount of data that has leaked. If the “safe” amount of information leakage has been reached, the dataset must be destroyed and rebuilt.
The acceptable amount of data that may be leaked is known as the “privacy budget”. The privacy budget will determine how many queries can be performed on the database and how accurate the results of those queries will be. The privacy budget must be calculated carefully. If the privacy budget is too large, too much sensitive information can be leaked. However, if the privacy budget is too low and a large amount of noise is added to the dataset, the results of the query will be inaccurate and therefore statistically useless.
When data may be modified in some way, differential privacy is the best technique to use. By adding random values to the dataset, any data, sensitive or nonsensitive, is protected. However, in cases where modifying data will affect the analysis, differential privacy is not the correct method and should not be used.
Conclusion
There is no perfect way to anonymize data. A single method is not enough to ensure that personally identifiable information is deduced. Utilizing multiple techniques to anonymize data is the ideal solution. Aggregation, for example, can be implemented using the k-anonymity technique. K-anonymity uses two other techniques, generalization and data suppression, to achieve anonymity. At this time, k-anonymity and differential privacy are the best solutions to anonymize data. Each has its own strengths and weaknesses, depending on the circumstances in which it is applied.
Sources + Additional Information
Techniques to anonymize data >
Techniques used in the EU to anonymize data >
Academic paper on l-diversity >
A technical guide on anonymizing datasets >
NIST De-identifying government data sets >
More information on the NYC taxi driver data: